

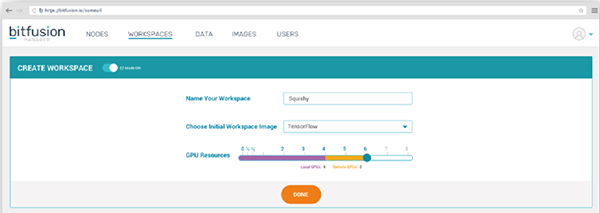
秒建工(gōng)作環境
Matrix Fusion在雲端預安裝主流深度學習框架、數據科學資(zī)料庫和GPU驅動,用戶無需耗費(fèi)時間搭建開(kāi)發環境,可在一(yī)分(fēn)鍾内通過簡單的鼠标點擊完成開(kāi)發環境設置,可以迅速靈活調用CPU和GPU資(zī)源。
智能化資(zī)源調度
Matrix Fusion 支持各類硬件及操作系統,提供端到端的基礎設施軟件解決方案,管理基礎CPU和GPU計算資(zī)源,能夠自動進行工(gōng)作負載資(zī)源調配。深度學習是同時利用CPU和GPU處理工(gōng)作負載的典型應用,Matrix Fusion通過整合用戶所有的硬件資(zī)源(集群亦或是單機)成爲CPU+GPU資(zī)源池,再将資(zī)源根據開(kāi)發者需要重新分(fēn)配CPU和GPU到開(kāi)發者的虛拟環境下(xià),管理員(yuán)也可以将多餘的計算資(zī)源靈活分(fēn)配給其他用戶或更爲嚴苛的工(gōng)作負載。
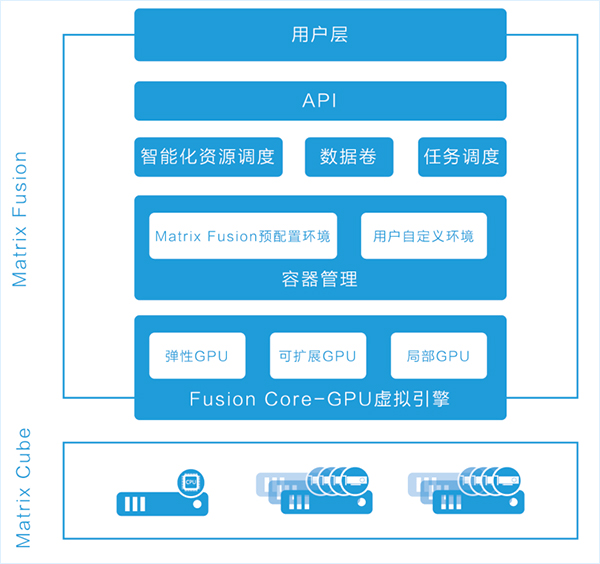
用戶在不同的虛拟環境中(zhōng)可以選擇在CPU資(zī)源上開(kāi)發,然後在GPU資(zī)源中(zhōng)測試,需要擴展訓練到更多GPU上時,可立即調用虛拟環境中(zhōng)任意數量的GPU資(zī)源。
容器管理
Matrix Fusion 構建于強大(dà)的計算硬件和GPU虛拟化的基礎上,搭載了全方位的容器管理方案。核心負載引擎容器化,是作爲極大(dà)簡化深度學習和AI工(gōng)作流程的最新技術,在金錢、人力、時間上投資(zī)不菲。而Matrix Fusion無需進行個性化調整,用戶隻需登錄操作界面,就可以直接調用專業化容器解決方案。 Matrix Fusion容器管理層包括1個内置資(zī)源庫,可以管理預配置容器(包括了每一(yī)種部署場景或個性化生(shēng)成容器): 預配置環境:Matrix Fusion預配置最新的深度學習框架和數據科學數據庫,用戶可以直接使用TensorFlow、Caffe、Torch以及其他社區的最新技術版本。 DIY開(kāi)發環境:用戶可以利用“工(gōng)作區快照”或“調入容器”來修改并保存容器環境,DIY一(yī)個更貼合自己使用習慣的開(kāi)發環境。Matrix Fusion “調入容器”可以爲用戶提供一(yī)個簡約的容器(僅含操作系統、最低配置的數據庫和驅動要求),用戶自行修改環境,然後上載作爲标準環境進行後續開(kāi)發。 用戶可以通過“工(gōng)作區快照”利用“Docker保存”工(gōng)作流程來複制環境,修改後保存到資(zī)源庫中(zhōng),以便于下(xià)一(yī)次的開(kāi)發工(gōng)作。 容器導出:容器可導出,作爲推理或其他生(shēng)産部署要求用。
Fusion Core
Matrix Fusion強大(dà)的靈活性來源于Fusion Core計算虛拟化引擎。Fusion Core控制應用和基礎GPU計算之間的API調用指示,允許GPU負載靈活分(fēn)布于本地GPU内存、網絡附加GPU、擴展至高達64個GPU,提供強大(dà)的整體(tǐ)性能。
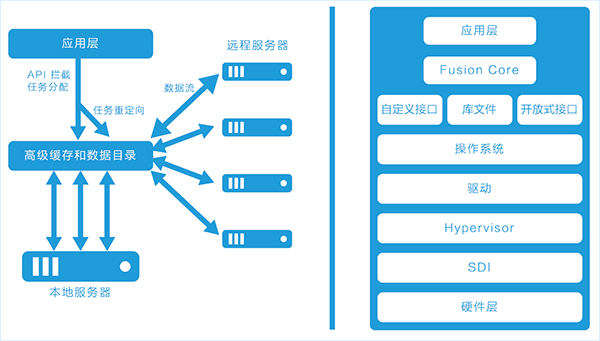
因爲Fusion Core采用的是“透明”模式而非虛拟層或其他虛拟化方式,所以不需要對基礎硬件或虛拟機環境做任何改變,也不需要改變應用編程本身。這意味着AI開(kāi)發者和數據科學家可以無縫利用GPU虛拟化的優勢,且将成本和集成需求降至最低。
數據卷
深度學習和AI工(gōng)作負載所需數據通常來源廣泛,既有線上也有線下(xià),既有外(wài)部也有内部,既有批量文件也有文件系統等等。Matrix Fusion能夠簡化處理工(gōng)作數據,讓管理員(yuán)明确網絡附加存儲位置并映射到容器中(zhōng)。隻要主機能夠訪問數據地址,容器就可以訪問數據,這讓AI開(kāi)發者和數據科學家的工(gōng)作大(dà)幅簡化. 此外(wài),系統還支持靈活、無限制的數據映射,Matrix Fusion支持每個節點的本地NFS文件系統。這一(yī)默認選項提供了工(gōng)作負載的标準地址,無論運行多大(dà)的深度學習工(gōng)作負載(包括運行在多服務器之間的),都可以快速獲取運行任務所需的數據
